编辑距离的计算
编辑距离是一个在实际应用和算法测试中都经常遇到的一个问题,它是对两个字符串差异化程度的一种量化度量,表示一个字符串至少需要经过多少次变换才能变成另外一个字符串。
首先,我们来看一个例子。相信各位开发者都用过版本控制程序 Git,当我们需要查看工作目录和暂存区状态的时候会用到命令 git status,这是一个非常常见的命令。如果手速较快,不小心将命令写成了 git statsu,那么我们会看到下面的提示
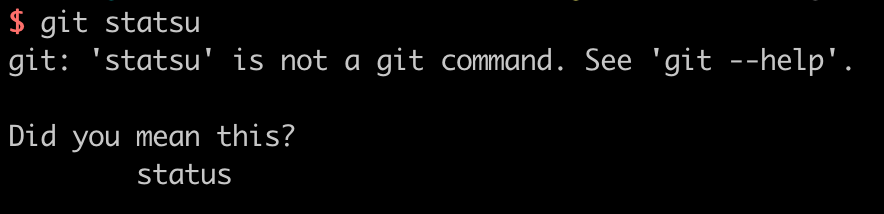
Git 会告诉我们 git statsu 拼写错了,要执行的命令是不是 git status。(Git 版本不同,提示的文字会有所不同,但含义都是一样的,笔者用的是 2.8.1 版本)。那么 Git 是怎么如此智能的知道我们想要执行的命令的呢?这就涉及到了本文的主题编辑距离。Git 会给出一个常用命令的列表,逐一计算每个命令与拼错的 statsu 之间的编辑距离,然后用编辑距离非常小的命令提示用户,于是我们会看到上面图片中的提示。
编辑距离根据允许的编辑操作的不同,有如下常见的几种:
- Levenshtein 距离 允许的操作有插入、删除和替换,常见的算法题中说的编辑距离指的就是 Levenshtein 距离。
- Damerau-Levenshtein 距离 在 Levenshtein 距离的基础上,还允许交换相邻的两个字符的位置,Git 中使用的就是 Damerau-Levenshtein 距离。
下面来看如何计算 Levenshtein 距离。假设两个字符串 string1 与 string2 的长度分别为 m 和 n,在计算 Levenshtein 距离的时候需要构造一个二维矩阵 d,行数为 m + 1,列数为 n + 1,矩阵中的某个元素 d[i][j] 表示 string1 的前 i 个字符与 string2 的前 j 个字符之间的 Levenshtein 距离,按照这种含义,那么 string1 与 string2 之间的 Levenshtein 距离就是 d[m][n],这样计算编辑距离的问题就转化为求解矩阵 d 的值。
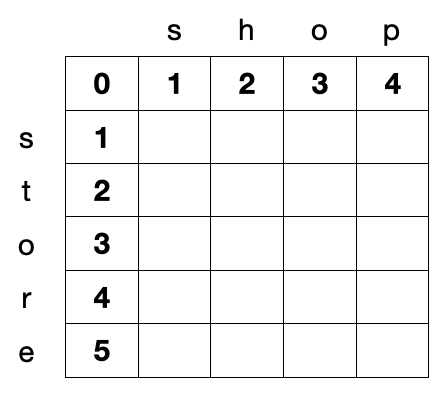
对于矩阵 d 我们其实是知道第 1 行和第 1 列的值的,第 1 行的元素可以用 d[0][j] 来表示,含义为 string1 的前 0 个字符与 string2 的前 j 个字符之间的 Levenshtein 距离,string1 的前 0 个字符其实就是空字符串,显然空字符串与任何其他字符串之间的 Levenshtein 距离都是该字符串的长度,因为只需要在空字符串中依次插入该字符串的每个字符就得到了该字符串。因此我们得到 d[0][j] = j,同理可以得到 d[i][0] = i。以 string1 = 'store',string2 = 'shop' 为例,矩阵 d 的初始状态如下
那么如何计算整个矩阵 d 的值呢?前面说过,对于 d 中的任一元素 d[i][j],表示 string1 的前 i 个字符与 string2 的前 j 个字符之间的 Levenshtein 距离。我们考虑下面两种情况:
-
如果 string1 的第 i 个字符与 string2 的第 j 个字符相等,也就是
string1[i - 1] == string2[j - 1],此时 string1 的前 i 个字符与 string2 的前 j 个字符之间的 Levenshtein 距离就等于 string1 的前 i - 1 个字符与 string2 的前 j - 1 个字符之间的 Levenshtein 距离,也就是d[i][j] = d[i - 1][j - 1],因为只需要把 string1 的前 i - 1 个字符变换成 string2 的前 j - 1 个字符,就得到了 string2 的前 j 个字符。 -
如果 string1 的第 i 个字符与 string2 的第 j 个字符不相等,根据 Levenshtein 距离定义,string1 的前 i 个字符变换为 string2 的前 j 个字符的最后一步操作只可能是插入、删除和修改中的某一个,下面分别看这 3 种情况:
- 如果最后一步是插入,那么需要将 string1 的前 i 个字符变换为 string2 的前 j - 1 个字符,最后一步插入
string2[j - 1]即可,这样至少需要d[i][j - 1] + 1步,因为将 string1 的前 i 个字符变换为 string2 的前 j - 1 个字符至少需要d[i][j - 1]步(矩阵 d 的含义如此),加上最后一步的插入操作,所以总共至少需要d[i][j - 1] + 1步。 - 如果最后一步是删除,那么需要将 string1 的前 i - 1 个字符变换为 string2 的前 j 个字符,最后一步删除 string1[i - 1],至少需要
d[i - 1][j] + 1步。 - 如果最后一步是修改,那么需要将 string1 的前 i - 1 个字符变换为 string2 的前 j - 1 字符,最后一步将
string1[i - 1]修改为string[j - 1],至少需要d[i - 1][j - 1] + 1步。
- 如果最后一步是插入,那么需要将 string1 的前 i 个字符变换为 string2 的前 j - 1 个字符,最后一步插入
对于上面 2 中的 3 种情况,只需要取步数最少的那种即可,因此我们可以得到下面的递推公式
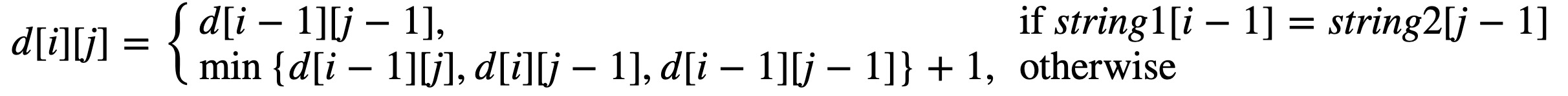
这种算法思想叫做动态规划,即可以通过子问题的最优解来推导出全局最优解。这里我们是比较 string1[i - 1] 与 string2[j - 1],然后通过 d[i - 1][j - 1]、d[i-1][j] 和 d[i][j - 1] 来推导 d[i][j] 的。
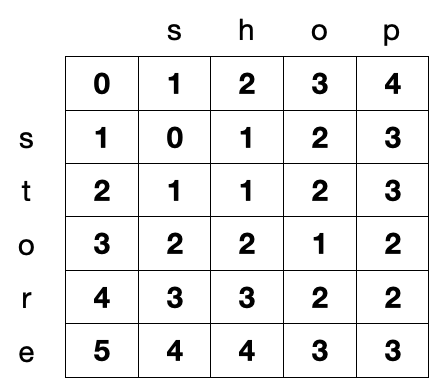
当计算出 d[m][n] 的时候,我们就得到了 Levenshtein 距离,对于上面的例子,我们最终得到的矩阵 d 如下
下面分别用 Python 和 Java 实现上述算法。
# Python 版本
def levenshtein_distance(string1, string2):
m = len(string1)
n = len(string2)
d = [[0] * (n + 1) for _ in range(m + 1)]
# 初始化第 1 列
for i in range(m + 1):
d[i][0] = i
# 初始化第 1 行
for j in range(n + 1):
d[0][j] = j
# 自底向上递推计算每个 d[i][j] 的值
for i in range(1, m + 1):
for j in range(1, n + 1):
if string1[i - 1] == string2[j - 1]:
d[i][j] = d[i - 1][j - 1]
else:
d[i][j] = min(d[i - 1][j], d[i][j - 1], d[i - 1][j - 1]) + 1
return d[m][n]
// Java 版本
public class LevenshteinDistance {
public int levenshteinDistance(String string1, String string2) {
int m = string1.length();
int n = string2.length();
int[][] d = new int[m + 1][n + 1];
// 初始化第 1 列
for (int i = 0; i < m + 1; i++) {
d[i][0] = i;
}
// 初始化第 1 行
for (int j = 0; j < n + 1; j++) {
d[0][j] = j;
}
// 自底向上递推计算每个 d[i][j] 的值
for (int i = 1; i < m + 1; i++) {
for (int j = 1; j < n + 1; j++) {
if (string1.charAt(i - 1) == string2.charAt(j - 1)) {
d[i][j] = d[i - 1][j - 1];
} else {
d[i][j] = Math.min(Math.min(d[i - 1][j], d[i][j - 1]), d[i - 1][j - 1]) + 1;
}
}
}
return d[m][n];
}
}
算法的空间复杂度和时间复杂度都为 O(m*n)。
我们再来观察一下 d[i][j] 的更新过程会发现,d[i][j] 只与 d[i - 1][j - 1]、d[i-1][j] 和 d[i][j - 1] 有关,也就是说矩阵 d 中某一行的元素只与当前行和上一行的元素有关,因此我们没有必要构造矩阵 d,只需要用两个数组分别表示当前行和上一行即可,改进后算的算法实现如下
# Python 版本
def levenshtein_distance(string1, string2):
m = len(string1)
n = len(string2)
# 初始化第 1 行
previous_row = [j for j in range(n + 1)]
current_row = [0] * (n + 1)
for i in range(1, m + 1):
# 对每行的第 1 个元素赋值为当前行号,也就是初始化了第 1 列,等价于 d[i][0] = i
current_row[0] = i
for j in range(1, n + 1):
# previous_row[x] 等价于 d[i - 1][x],current_row[x] 等价于 d[i][x]
if string1[i - 1] == string2[j - 1]:
current_row[j] = previous_row[j - 1]
else:
current_row[j] = min(previous_row[j], current_row[j - 1], previous_row[j - 1]) + 1
# 将上一行更新为当前行,循环结束之后 previous_row 就是原矩阵 d 中的最后一行
previous_row = current_row[:]
return previous_row[n]
// Java 版本
public class LevenshteinDistance {
public int levenshteinDistance(String string1, String string2) {
int m = string1.length();
int n = string2.length();
int[] previousRow = new int[n + 1];
int[] currentRow = new int[n + 1];
// 初始化第 1 行
for (int j = 0; j < n + 1; j++) {
previousRow[j] = j;
}
for (int i = 1; i < m + 1; i++) {
// 对每行的第 1 个元素赋值为当前行号,也就是初始化了第 1 列,等价于 d[i][0] = i
currentRow[0] = i;
for (int j = 1; j < n + 1; j++) {
// previousRow[x] 等价于 d[i - 1][x],currentRow[x] 等价于 d[i][x]
if (string1.charAt(i - 1) == string2.charAt(j - 1)) {
currentRow[j] = previousRow[j - 1];
} else {
currentRow[j] = Math.min(Math.min(previousRow[j], currentRow[j - 1]), previousRow[j - 1]) + 1;
}
}
System.arraycopy(currentRow, 0, previousRow, 0, n + 1);
}
return previousRow[n];
}
}
这样,我们就将空间复杂度降到了 O(n),由于可以将 string1 和 string2 对调或者按照列遍历,所以理论上空间复杂度为 O(min(m, n))。其实还可以进一步优化,上面的程序在更新 currentRow[j] 时,j 之后的元素都没有使用到,因此可以用 current_row 在 j 之后(包含 j)的空间保存 previous_row 在 j 之后的元素,而 previous_row 在 j 之前的元素只有 previous_row[j - 1] 会被使用到,可以单独用一个变量保存该值,于是可以少用一个数组,实现如下
# Python 版本
def levenshtein_distance(string1, string2):
m = len(string1)
n = len(string2)
# 初始化第 1 行
row = [j for j in range(n + 1)]
for i in range(1, m + 1):
# pre 等价于 d[i-1][j-1]
pre = row[0]
row[0] = i
for j in range(1, n + 1):
# 在给 row[j] 赋值前,row[j] 等价于 d[i-1][j], row[j-1] 等价于 d[i][j-1]
tmp = row[j]
if string1[i - 1] == string2[j - 1]:
row[j] = pre
else:
row[j] = min(row[j], row[j - 1], pre) + 1
pre = tmp
return row[n]
// Java 版本
public class LevenshteinDistance {
public int levenshteinDistance(String string1, String string2) {
int m = string1.length();
int n = string2.length();
int[] row = new int[n + 1];
// 初始化第 1 行
for (int j = 0; j < n + 1; j++) {
row[j] = j;
}
for (int i = 1; i < m + 1; i++) {
// pre 等价于 d[i-1][j-1]
int pre = row[0];
row[0] = i;
for (int j = 1; j < n + 1; j++) {
// 在给 row[j] 赋值前,row[j] 等价于 d[i-1][j], row[j-1] 等价于 d[i][j-1]
int tmp = row[j];
if (string1.charAt(i - 1) == string2.charAt(j - 1)) {
row[j] = pre;
} else {
row[j] = Math.min(Math.min(row[j], row[j - 1]), pre) + 1;
}
pre = tmp;
}
}
return row[n];
}
}
上面介绍了 Levenshtein 距离的具体解法,对于 Damerau-Levenshtein 距离,只需要在上述解法的基础上再加一个交换相邻字符的操作就可以了,Python 解法如下
# Python 版本
def damerau_levenshtein_distance(string1, string2):
m = len(string1)
n = len(string2)
d = [[0] * (n + 1) for _ in range(m + 1)]
# 初始化第 1 列
for i in range(m + 1):
d[i][0] = i
# 初始化第 1 行
for j in range(n + 1):
d[0][j] = j
# 自底向上递推计算每个 d[i][j] 的值
for i in range(1, m + 1):
for j in range(1, n + 1):
if string1[i - 1] == string2[j - 1]:
d[i][j] = d[i - 1][j - 1]
else:
d[i][j] = min(d[i - 1][j], d[i][j - 1], d[i - 1][j - 1]) + 1
if i > 1 and j > 1 and string1[i - 1] == string2[j - 2] and string1[i - 2] == string2[j - 1]:
d[i][j] = min(d[i][j], d[i - 2][j - 2] + 1)
return d[m][n]
Git 使用的就是 Damerau-Levenshtein 距离,不过对于每个操作都赋予了不同的权重,交换、修改、增加和删除的权重分别是 0、2、1 和 3。上面我们的代码中默认所有操作的权重都是 1。
至此,关于编辑距离的介绍就结束了。最后要说的是,关于编辑距离的解法以及各种优化方法其实不是那么容易想出来的,至少对于我来说如此,我们能做的是看了之后能够理解,工作中遇到类似的问题知道有编辑距离这个工具可以使用。